

예문에 후리가나 적용하기


- Name
- Link
들어가며
일단냥은 사용자가 어떻게 하면 단어장을 더 편하고 쉽게 볼 수 있을까 고민하며 개선하려고 노력하고 있습니다.
이번에는 예문에 후리가나를 적용하게 되면서 단어장의 가독성이 크게 늘어났는데요. 본 게시글에서는 후리가나를 적용하면서 겪었던 고민거리와 이슈들을 소개해 드리겠습니다.
후리가나란?
일본어의 상용한자는 2,136자로 일본인들도 모든 한자를 기억할 수 없습니다. 그래서 일본에서는 한자 위에 발음을 표시해 주는 문자인 후리가나를 사용하고 있습니다. 
기존 일단냥의 예문 표기
기존의 일단냥에서는 예문의 발음을 후리가나로 표기하는 것이 아닌 한자와 히라가나를 포함한 모든 문장을 히라가나로 표기했었습니다.

이렇게 히라가나로 나열된 발음 표기에는 치명적인 단점 2개가 있었습니다.
- 나열된 히라가나에서 한자에 대한 발음을 사용자가 찾아야 했습니다.
- 예문에 불필요하게 히라가나가 중복 표기되었습니다.
이러한 단점은 학습자 입장에서 가독성을 떨어트려 빠르게 개선하고자 했습니다.
첫 번째 방법
후리가나를 적용하기 위해 첫 번째로 생각한 방법은 심플하게 기존의 예문 히라가나 데이터를 활용하는 것이었습니다.
예문 히라가나 : きょうしつにのこっておそうじをします
예문 : 教室に残ってお掃除をします
예문 뜻 : 교실에 남아서 청소를 해요
예문인 '教室に残ってお掃除をします'와 예문 히라가나인 'きょうしつにのこっておそうじをします'를 비교해서 겹치는 문자를 추출하면 に, って, お, をします라는 배열을 얻을 수 있습니다.
겹치는 문자의 배열로 아래와 같이 가공할 수 있습니다.
예문 히라가나 : [きょうしつ, に, のこって, お, そうじ, をします]
예문 : [教室, に, 残, って, お, 掃除, をします]
이러면 배열 순서에 맞게 한자에 상응하는 후리가나를 달 수 있게 됩니다.
하지만 이 방법은 예문의 모든 종류의 후리가나를 표기하기에 적합하지 않았습니다.
예문 히라가나 : [いまさむらい, が, く, る]
예문 : [今侍, が, 来, る]
이 예제를 보면 今와 侍는 분리된 단어인데 분리되지 않고 하나의 단어로 인식하고 있습니다. 그래서 今와 侍의 후리가나는 어디까지인지 알 수 없게 됩니다.
이는 겹치는 히라가나로만 단어를 구분하기에 이런 예외가 발생한 것입니다. 그래서 해당 방법으로 후리가나를 구현하지 못했습니다.
두 번째 방법
두 번째로 생각한 방법은 일본어 형태소 분석기를 사용하는 것입니다.
찾아본 형태소 분석기 라이브러리로는 wanakana, mecab, kruoshiro가 있었는데 일단냥에 적합한 분석기를 찾기 위해 전부 사용해 보았습니다.
wanakana
wanakana는 히라가나, 카나카나를 로마자로 혹은 로마자를 히라가나, 카타카나로 변환하는 기능과 해당 문자열이 히라가나인지 카타카나인지 boolean으로 구분할 수 있는 후리가나와 상관없는 기능들만 있어서 채택되지 않았습니다.
mecab
mecab은 진짜 말 그대로 형태소를 분석해줬습니다.
요청
いつもニコニコあなたの隣に這い寄る混沌ニャルラトホテプです!
결과
[ [ 'いつも', '副詞', '一般', '*', '*', '*', '*', 'いつも', 'イツモ', 'イツモ' ],
[ 'ニコニコ', '副詞', '助詞類接続', '*', '*', '*', '*', 'ニコニコ', 'ニコニコ', 'ニコニコ' ],
[ 'あなた', '名詞', '代名詞', '一般', '*', '*', '*', 'あなた', 'アナタ', 'アナタ' ],
[ 'の', '助詞', '連体化', '*', '*', '*', '*', 'の', 'ノ', 'ノ' ],
[ '隣', '名詞', '一般', '*', '*', '*', '*', '隣', 'トナリ', 'トナリ' ],
[ 'に', '助詞', '格助詞', '一般', '*', '*', '*', 'に', 'ニ', 'ニ' ],
[ '這い', '動詞', '自立', '*', '*', '五段・ワ行促音便', '連用形', '這う', 'ハイ', 'ハイ' ],
[ '寄る', '動詞', '自立', '*', '*', '五段・ラ行', '基本形', '寄る', 'ヨル', 'ヨル' ],
[ '混沌', '名詞', '一般', '*', '*', '*', '*', '混沌', 'コントン', 'コントン' ],
[ 'ニャルラトホテプ', '名詞', '一般', '*', '*', '*', '*', '*' ],
[ 'です', '助動詞', '*', '*', '*', '特殊・デス', '基本形', 'です', 'デス', 'デス' ],
[ '!', '記号', '一般', '*', '*', '*', '*', '!', '!', '!' ] ]
동사, 명사, 발음 등.. 여러 유용한 값을 리턴해줍니다. 일단냥에서 후리가나로 쓰기에는 많은 요소를 리턴해줬고 무엇보다 한자의 발음을 히라가나가 아닌 카타카나로 리턴해주는 단점이 있어 채택되지 못했습니다.
kruoshiro
kruoshiro는 '홈페이지에서 후리가나 및 오쿠리가나 모드가 지원되는 일본어 문장을 히라가나, 가타카나 또는 로마자로 변환하기 위한 일본어 라이브러리.' 라는 설명을 하고 있습니다.
요청
kuroshiro.convert("教室に残ってお掃除をします", {mode:"furigana", to:"hiragana"});
결과
<ruby>教室<rp>(</rp><rt>きょうしつ</rt><rp>)</rp></ruby>に<ruby>残<rp>(</rp><rt>のこ</rt><rp>)</rp></ruby>ってお<ruby>掃除<rp>(</rp><rt>そうじ</rt><rp>)</rp></ruby>をします
리턴값은 후리가나를 편하게 달 수 있게 ruby 태그로 감싸주었습니다. 또한 해당 라이브러리 소개만 봐도 후리가나를 적용하기 위한 일단냥에 맞춤인 라이브러리였습니다.
Krushiro로 후리가나 적용하기
Krushiro로 가공 받은 데이터는 후리가나 표기를 위한 ruby 태그가 포함되어 있는데 ruby 태그는 React Native에는 지원하지 않는 태그였습니다. mode를 okurigana로 해서 표기를 편하게 할까 했는데, 일단냥 팀에서 예문을 수정하기 위해 웹에서 관리자 페이지를 만들어야 하기에 ruby 태그로 정규 표현식을 사용해 데이터를 구성하였습니다.
- ruby 태그 안의 문자열 추출
.split(/<ruby>(.*?)<\/ruby>/g)
- rt(후리가나)와 rp(오쿠리가나) 태그 안의 문자열 제거해 후리가나, 오쿠리가나를 제외한 예문 추출
.replace(/<\/?rt>/g, "")
.replace(/<rp>\(.*?\)<\/r```p>/g, "");
- rt(후리가나) 태그 안에서 후리가나 추출 만약 후리가나가 없으면 빈 문자열
.match(/<rt>(.*?)<\/rt>/) || " ";
- 가공된 데이터 예시
{"furigana": "きょうしつ", "reibun": "教室"},
{"furigana": " ", "reibun": "に"},
{"furigana": "の", "reibun": "残"},
{"furigana": " ", "reibun": "ってお"},
{"furigana": "そうじ", "reibun": "掃除"},
{"furigana": " ", "reibun": "をします"},
다소 난잡하지만 정규 표현식으로 예문 위치에 들어갈 배열과 후리가나 위치에 들어갈 배열을 만들어 후리가나를 적용할 수 있었습니다.
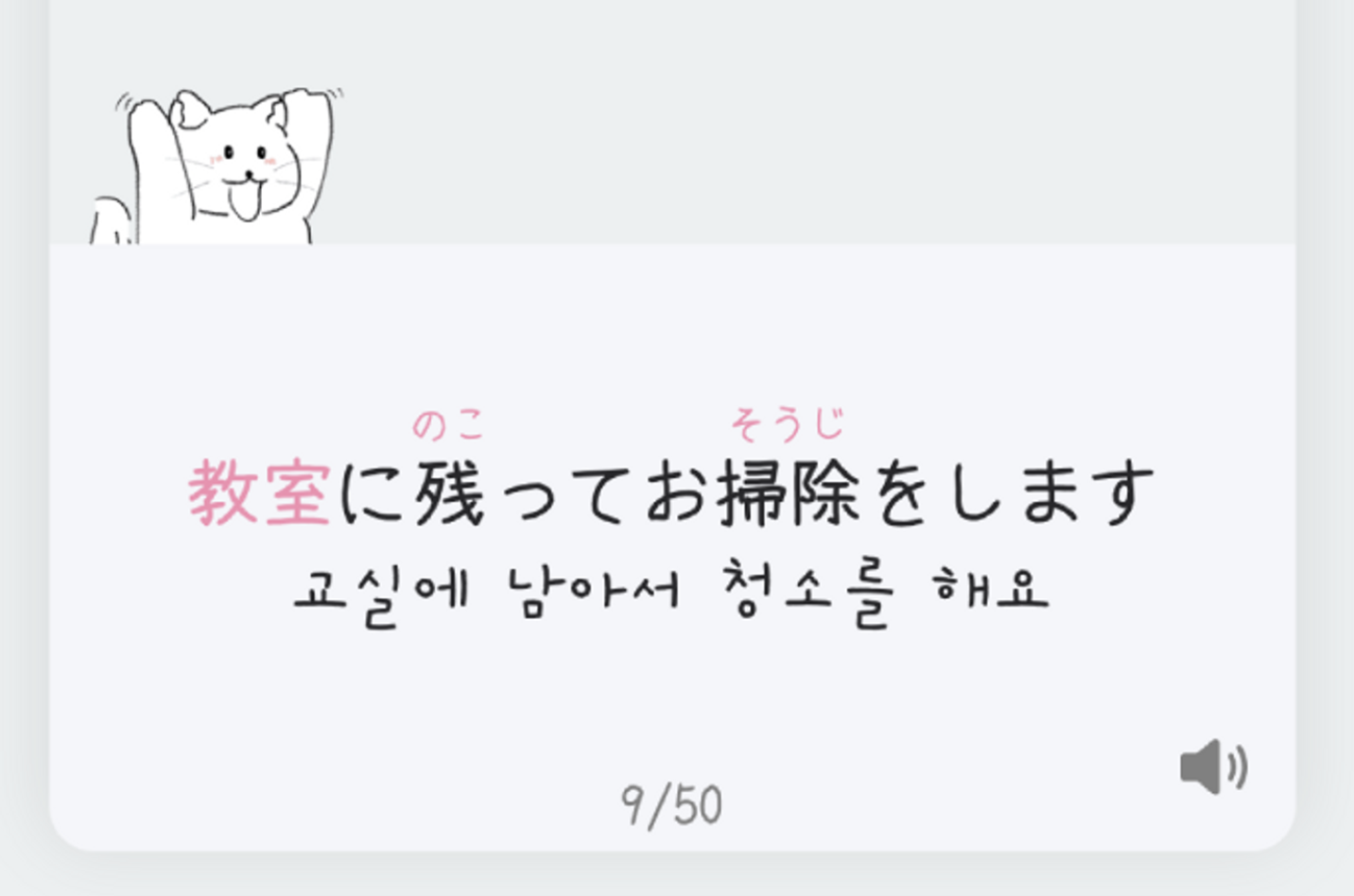
그리고 예문을 수정하는 관리자 페이지에서는 ruby 태그로 인해 쉽게 적용 할 수 있었습니다.
이슈
예문에 긴 공백으로 표기되는 이슈
후리가나가 존재하지 않은 채 문장이 길게 이어지면 단어가 순서대로 나열되지 않고 큰 공백이 생겨 줄바꿈 처리가 되는 이슈가 있었습니다. 
후리가나를 적용하기 위해 가공된 데이터를 보면 아래와 같습니다.
{"furigana": " ", "reibun": "この"},
{"furigana": "きょうかい", "reibun": "教会"},
{"furigana": " ", "reibun": "はいつ"},
{"furigana": "た", "reibun": "建"},
{"furigana": " ", "reibun": "てられたの"},
てられたのですか라는 문자열이 너무 길기 때문에 예문 박스에 해당 범위를 넘어서면 줄바꿈이 되었던 것입니다.
위의 3번을 다시 봅시다.
- rt(후리가나) 태그안에서 후리가나 추출 만약 후리가나가 없으면 빈 문자열
.match(/<rt>(.*?)<\/rt>/) || " ";
이라는 조건이 있었는데 이게 핵심입니다. 빈 문자열을 넣는 이유는 모든 문자열을 1개씩 분리하기위해서 입니다. 그래야 てられたのですか 처럼 길어지지 않고 무조건 1개의 문자열로 존재하기 때문이죠
// hugigana가 " " 공백이고 reibun이 2글자 이상일 때 한자나 후리가나가 아니기에 1개씩 쪼개서 배열로 저장합니다.
if (furigana === " " && reibun.length >= 2) {
return Array.from(reibun).map((character) => ({
furigana: " ",
reibun: character,
}));
} else {
return [{ furigana, reibun }];
}
[
{"furigana": " ", "reibun": "こ"},
{"furigana": " ", "reibun": "の"},
{"furigana": "きょうかい", "reibun": "教会"},
{"furigana": " ", "reibun": "は"},
{"furigana": " ", "reibun": "い"},
{"furigana": " ", "reibun": "つ"},
{"furigana": "た", "reibun": "建"},
{"furigana": " ", "reibun": "て"},
{"furigana": " ", "reibun": "ら"},
{"furigana": " ", "reibun": "れ"},
{"furigana": " ", "reibun": "た"},
{"furigana": " ", "reibun": "の"},
]
이런식으로 후리가나가 없는 문자열도 1개씩 분리해 이슈를 해결할 수 있었습니다.

한자+히라가나로 이루어진 단어를 별개의 단어로 인식하는 문제
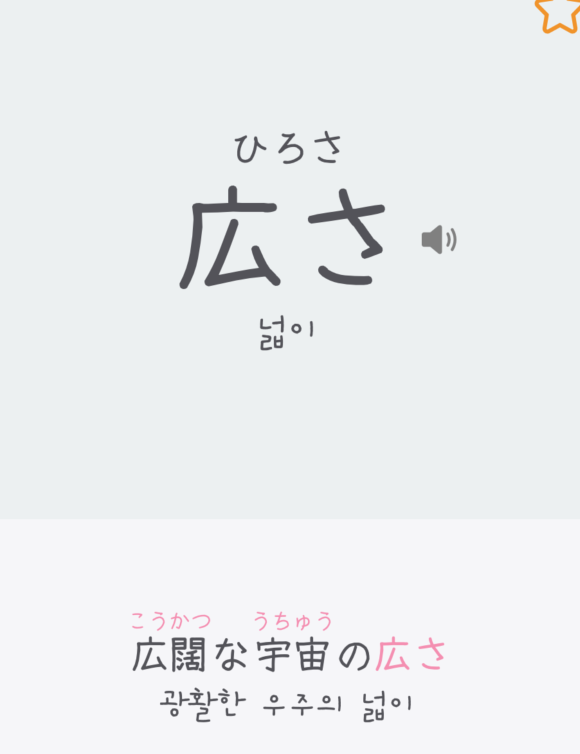
kuroshiro가 한자+히라가나로 이루어진 단어를 후리가나를 달아주기 위해 広さ라는 단어에서 広라는 한자만 후리가나를 달아줘 아래처럼 분리가 됩니다.
<ruby>広<rp>(</rp><rt>ひろ</rt><rp>)</rp></ruby>さ
{"furigana": "ひろ", "reibun": "広"},
{"furigana": " ", "reibun": "さ"},
 분명 후리가나를 위해 단어가 분리된 건 매우 좋은 상황입니다. 하지만 사용자의 더 나은 학습을 위해 예문에 현재 보고 있는 단어를 빨간색 폰트로 바꾸고 싶었고 추후 추가될 문제풀이 기능에도 필요했습니다..
분명 후리가나를 위해 단어가 분리된 건 매우 좋은 상황입니다. 하지만 사용자의 더 나은 학습을 위해 예문에 현재 보고 있는 단어를 빨간색 폰트로 바꾸고 싶었고 추후 추가될 문제풀이 기능에도 필요했습니다..
이 예시처럼 한자+히라가나로 이루어진 단어를 한 개의 단어로 인식해 빨간색 폰트로 바꾸는 방법은 간단했습니다.
먼저 예문에서 현재 단어인 広さ를 _로 변경합니다.
변환 : 예문.replace(new RegExp(단어, "g"), "_");
결과 : 広闊な宇宙の_
결과값인 広闊な宇宙の_ 문자열로 kuroshiro를 통해 후리가나를 달면 됩니다.
[{"furigana": "こうかつ", "reibun": "広闊"},
{"furigana": " ", "reibun": "な"},
{"furigana": "うちゅう", "reibun": "宇宙"},
{"furigana": " ", "reibun": "の"},
{"furigana": " ", "reibun": "_"}]
가공된 해당 데이터로 화면에 표기할 때 _를 캐치해서 단어장의 단어와 히라가나를 넣어주면 됩니다.
if (item.reibun === "_") {
return { furigana: tangoHurigana, reibun: tango };
}
마무리
지금까지 일단냥 예문에 후리가나를 적용하면서 겪은 고민거리와 이슈들을 살펴봤습니다. 일단냥이 항상 사용자에게 좋은 경험을 제공하기 위해 어떤 노력과 고민을 하고 있는지 소개할 수 있어서 좋았습니다.
추가적으로 혼자서 개발했던 일단냥이 이제는 디자이너가 합류하게 되어 지금처럼 점점 개선될 예정이니 많은 기대 바랍니다.